
I’ve recently been playing more with Terraform and while there are various sources online which show how to build out a VM, VNET, RG etc it all seemed basic and I struggled to find anything which showed what an environment might look like in a typical production environment. So I have been developing one myself and what it might look like and will develop as I go. If you like what you’ve read below and/or have opinions on how something should be done, please reach out! =)
List of things to-do / wants / needs:
- Connect new resources to existing resources, such as a new VM to an existing VNET.
- Utilize re-usable code, to minimize duplication and complexity.
- Ability to make changes where needed without affecting all states.
- Automate the process of code delivery into artifacts.
- Introduce a authorization process, to review code before state amendments.
- CD/CD via Azure DevOps, using pipelines and releases.
1. Connecting to existing resources
I found this relatively easy to-do, you just use a data block to refer to existing resources so these can be used as a variable.
In the below example, I’m referencing the RG and VNET, now these values are not in the statefile to Terraform is taking my word for it and will use those values, as these resources were not built within the statefile im referencing.
I am also using fisontech are my reference for this on each value where needed to ensure if I needed to, I could use another RG or VNET in my main.tf
The below code will therefore, deploy a NIC and join the subnet of the vnet I specify, pretty cool!
data "azurerm_resource_group" "fisontech" {
name = "fisontech-rg"
}
data "azurerm_subnet" "fisontech" {
name = "default"
virtual_network_name = "Fisontech-vnet"
resource_group_name = "fisontech-rg"
}
resource "azurerm_network_interface" "fisontech" {
name = "nic-ftech"
location = "${data.azurerm_resource_group.fisontech.location}"
resource_group_name = "${data.azurerm_resource_group.fisontech.name}"
ip_configuration {
name = "testconfiguration1"
subnet_id = "${data.azurerm_subnet.fisontech.id}"
private_ip_address_allocation = "Dynamic"
}
}
Utilize re-usable code
The ability to re-use code, from what I have found so far is primarily by using modules. These can define sets of resources, such as VMs etc.
So an example would be a VM like below. It allows us to reference this VM type in our main.tf file, rather than having to specify the same thing every time we need to build a VM, we can just say use this module.
resource "azurerm_windows_virtual_machine" "vm" {
name = var.vmname
resource_group_name = var.resource_group_name
location = var.location
size = var.vm_size
admin_username = var.admin_usename
admin_password = var.admin_password
network_interface_ids = var.network_interface_ids
os_disk {
name = "${var.vmname}-os-disk-01"
caching = "ReadWrite"
storage_account_type = var.os_disk_type
}
source_image_reference {
publisher = var.image_publisher
offer = var.image_offer
sku = var.image_sku
version = "latest"
}
}
The var. variables are set from within the same dir as the module, e.g:
variable "vm_size" {
type = string
description = "The size of the virtual machine"
}
So this means I can build out my main.tf file like:
data "azurerm_resource_group" "fisontech" {
name = "fisontech-rg"
}
data "azurerm_subnet" "fisontech" {
name = "default"
virtual_network_name = "Fisontech-vnet"
resource_group_name = "fisontech-rg"
}
module "network-interface" {
source = "../../modules/network-interface"
vmname = var.vmname
location = "${data.azurerm_resource_group.fisontech.location}"
resource_group_name = "${data.azurerm_resource_group.fisontech.name}"
subnet_id = "${data.azurerm_subnet.fisontech.id}"
}
So you can see how using connecting to existing resources using code blocks and modules can make deploying IaC in Terraform alot easier, while also making code easier to read and tidier.
Change code without affecting all states
The idea is instead of having 1 big statefile to manage, I break it down into individual statefiles like below:
- Storage location (Azure Container) > statefolder > resource1
- Storage location (Azure Container) > statefolder > resource2
- Storage location (Azure Container) > statefolder > resource3
So if I change resource1, it wont affect resource2.
Automate code into artifacts within Azure DevOps via Pipelines
So what I want to happen, is when I commit changes such as a new VM etc, this code will be stored somewhere so it can be referenced later on.
I did this by firstly cloning the repo down to my local machine, making a change and committing it. The code then goes through a pipeline which will copy files from a specific folder in my repo to $(Build.ArtifactStagingDirectory), it will then publish this path as an artifact which can be referenced later on in my release pipeline. Initially I didnt have CI enabled on this as I wanted to kick this cycle off manually so see the process, but quickly found once I was happy with the process, that running the job automatically once a commit had been made was a real time saver, which was enabled by selecting CI within the trigger section of the pipelines.
Introduce an authorization process
I introduced an auth method, which means that when someone kicks off a release pipeline it will first wait for an approval, so someone will go in and check the code changes and then approve it with a little message, the pipeline would then go through its cycle and complete.
So firstly someone would submit the change, via following:
- Commit changes in VSC to Azure Dev Ops repo.
- Code goes into artifacts as per previous section.
- A release pipeline sees the changes to the artifacts and is deployed awaiting approval.
- Approval as made via admin.
- Job runs and completes.
A few screenshots below show this:
So I am changing the vm size of dp3 from DS1_v2 to D2_v2 - a fairly standard cloud admin change to made via Terraform code I submitted which has gone through VSC on my local machine.
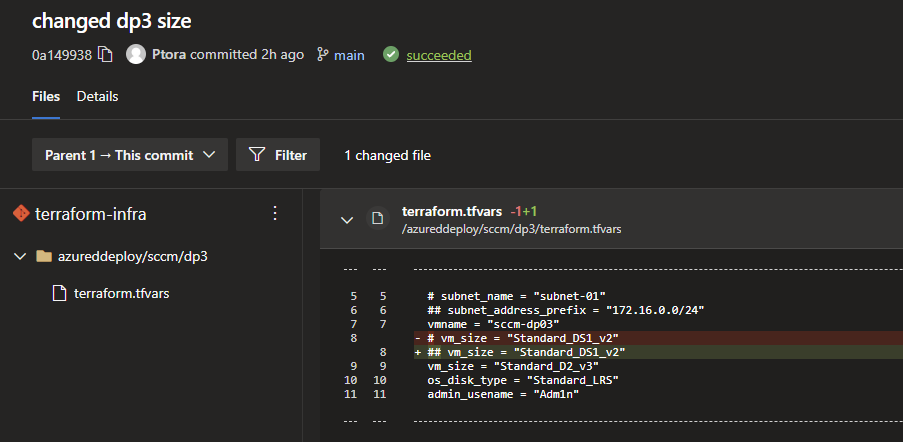
As the admin I then go in and approve, put a little message and press approve.
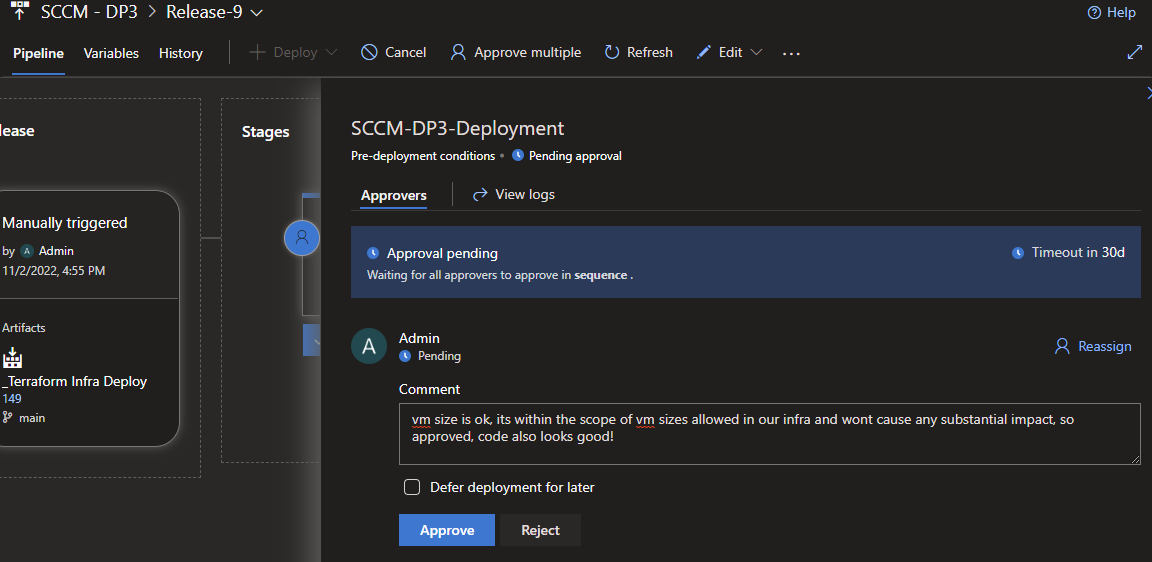
The next screen shows its been approved with my message displayed.

As a result of the approval, the release then continues its job which will eventually complete.
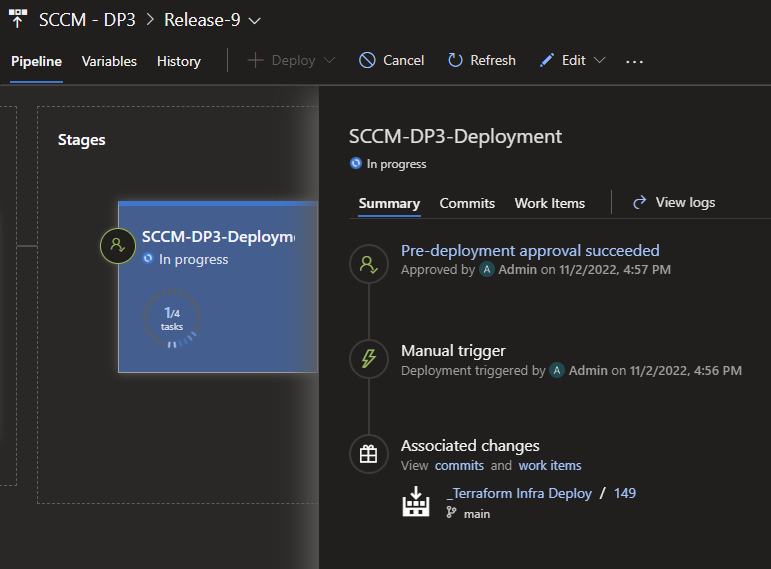
Pipelines and release automation
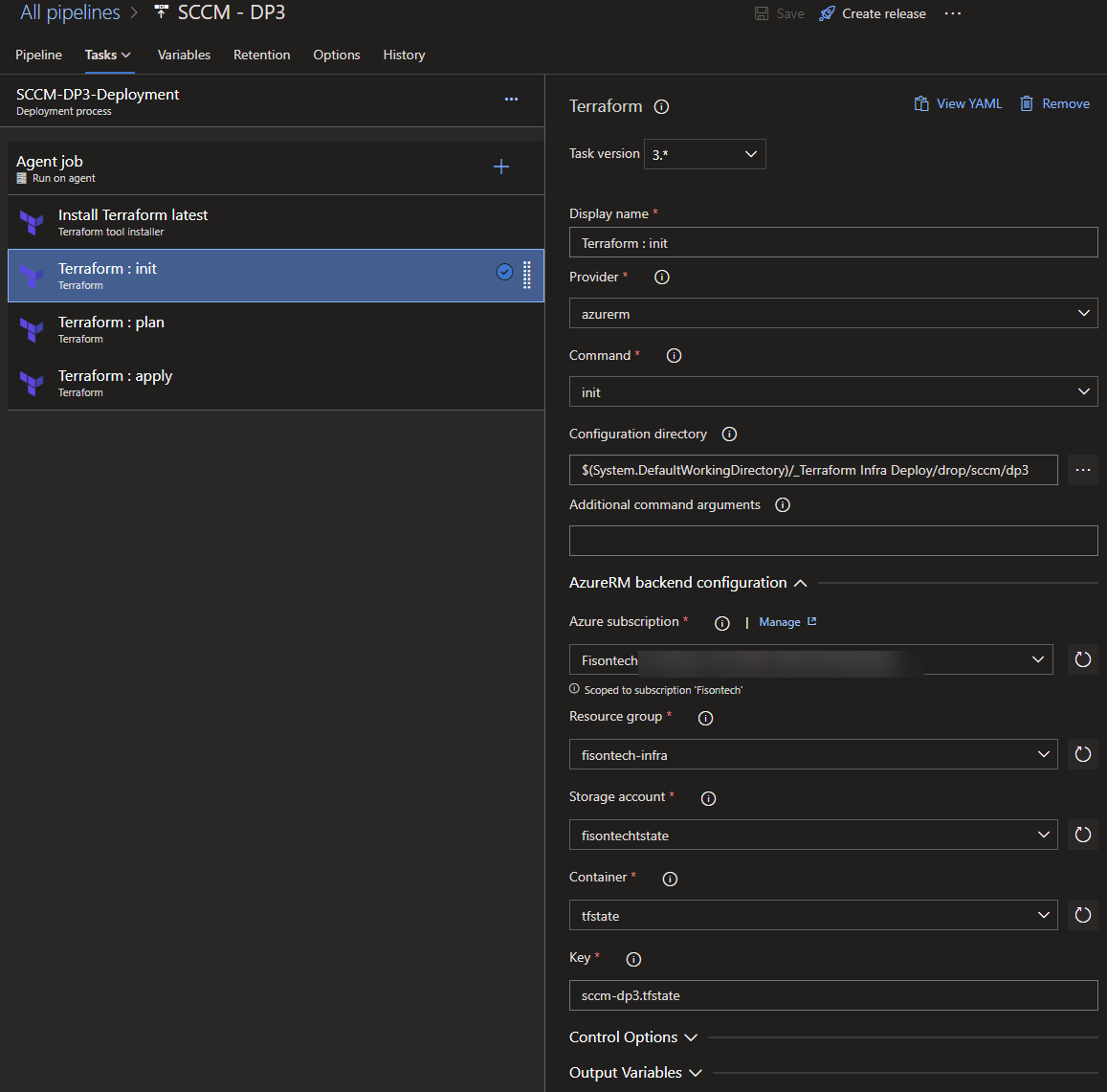
I built out a pipeline which essentially has 4 steps.
- Install Terraform on an agent (using Azure, but intention is to run it on a Pi4 as Linux is much faster and less resource hungry)
- Initialize Terraform, this will fire up all the files needed onto the agent box.
- Plan out the deployment.
- Apply the changes into production matching the state file.
You can see this is the artifacts, basically my TF code - in this instance the change is the same as the previous screenshots (vm size change).
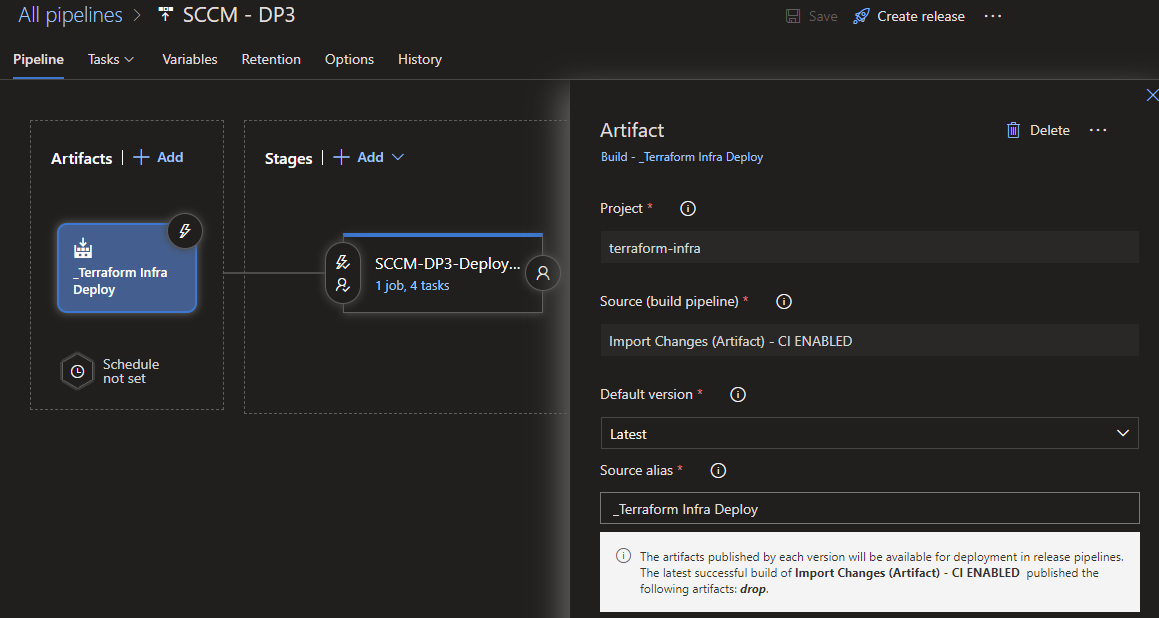
And here you can see where im specifying the steps, all of this is using an SPN thats setup for my sub which allows the pipeline to run jobs against my infrastructure automatically.
Summary
I have enjoyed this little project so far spending a couple days on it, can definitely see areas for improvement but fun!